10 AI Bioinformatics Startup Ideas Worth Building in 2026












The timing matters. Not in a hype-cycle way, but in the way a scientist notices when conditions finally align.
Industry analysts project strong growth for AI in bioinformatics over the coming decade, with multiple research firms estimating compound annual growth rates in the high teens — though specific figures vary significantly depending on methodology and market definition. That's not a bubble number. That's the slow, compounding growth of a field where sequencing costs have dropped faster than analysis costs, where foundation models for cellular biology have crossed from academic curiosity into production pipelines, and where regulators are finally catching up to the technology.
Governments and private institutions are investing heavily in genomic research, AI integration, and multiomics technologies. Meanwhile, bioinformatics and generative AI are accelerating genetic research by enabling faster data analysis and drug discovery.
What this creates is a specific kind of opportunity: problems that have existed for a decade, that domain experts know intimately, that have resisted solution because the tooling wasn't ready. In 2026, a meaningful portion of those problems are now tractable. The question is which ones are worth building a company around, and why.
This post profiles ten startup ideas across clinical genomics, translational science, manufacturing, and applied metagenomics. Each one is framed around the same three questions: what's the problem, what does the AI-native solution actually look like, and where does the durable competitive advantage come from.
1. Clinical Variant Curation and Reporting Copilot
Variant interpretation is a quality problem disguised as a throughput problem. In diagnostic labs processing panels, exomes, or genomes, the last mile is a human reviewer reading evidence, applying ACMG/AMP criteria, and writing a report. That process is slow, subject to inter-reviewer variability, and carries real clinical risk when a pathogenic variant gets buried under a backlog.
Interpretable scores, confidence estimates, and evidence aligned with ACMG/AMP guidelines are essential for successful clinical adoption of AI in variant work. The copilot version of this isn't a black-box classifier. It's a drafting tool: it assembles the evidence, applies the ACMG/AMP evidence codes (covering categories from population data to functional studies to computational predictors), applies any lab-specific rule modifications, and produces a report draft with citations the clinician can review rather than build from scratch.
Automating evidence assembly and applying ACMG/AMP guidelines to classify germline and somatic variants with consistency moves labs from filtered candidates to defensible clinical decisions. The moat here compounds in a specific way: every curated case that passes through the system enriches a proprietary database. Recurring variants auto-match prior annotations. Only genuinely novel variants need fresh curation. The database becomes more accurate and more complete with every case, and a competitor starting from scratch faces years of catch-up even with superior models.
Regulation makes this sticky in a second way. CLIA/CAP accreditation requirements, audit trails, and documentation standards mean switching costs are high once a lab has calibrated its workflows to the platform. The combination of regulatory friction and data flywheel is genuinely hard to dislodge.
2. Validation and Reproducibility Layer for Clinical NGS Pipelines
Most clinical bioinformatics pipelines were not built to be audited. They were built to work. Those two things are not the same.
As AI models move deeper into diagnostic workflows, the pressure to validate, document, and prove reproducibility grows rather than shrinks. A lab that can't demonstrate its pipeline produces consistent results across software versions, reference genome updates, or reagent batches will fail accreditation and lose clinical credibility.
The startup opportunity here is an AI-assisted platform for pipeline validation, drift detection, version control, and accreditation documentation. It's unglamorous infrastructure work, but that's precisely what makes it a business. The "compliance appreciates as AI proliferates" thesis is real: evolving FDA guidance for software as a medical device and in vitro diagnostics is reshaping what documentation and validation requirements look like — creating both new obligations and, for companies that meet them early, a potential route to differentiation. The same regulatory environment that creates opportunity also imposes significant new compliance burdens that founders should plan for explicitly.
Containerised pipelines, unit and integration tests, end-to-end accuracy benchmarks, and machine-readable accreditation documentation are not things most labs have the internal engineering bandwidth to build well. An external platform that handles this and keeps it current as CLIA/CAP and ISO 15189 standards evolve creates a recurring need that doesn't go away. The moat is regulatory trust plus the switching cost of re-validating against a new platform.
3. Biology-Native Data Harmonization Infrastructure
The bench produces data that no enterprise data platform was designed to handle. FASTQ files, BAM alignments, mass spectrometry outputs, ELN notes, assay metadata, plate reader exports: these don't live in tidy relational tables, and they don't slot neatly into a Snowflake schema.
The result is that most bioinformatics and ML work in wet-lab environments starts with weeks of manual ETL. Data science teams spend more time finding and cleaning data than building models. And when a researcher leaves, their data cleaning logic often leaves with them.
Cloud-based bioinformatics solutions are transforming biological data analysis, driving demand for platforms that offer scalable, secure, and collaborative environments for processing vast genomic and multiomic datasets. The AI-native version of this isn't a better data warehouse. It's a biology-literate ingest layer that understands file formats, instrument provenance, and assay context, and builds a per-customer knowledge graph that makes data queryable and model-ready.
This is the genomics version of the brownfield data play: the hard, unglamorous ETL nobody wants to do, where the proprietary data graph built for each customer becomes the moat. The more data flows through the platform, the richer the graph, and the harder it becomes to reconstruct that context elsewhere.
4. Spatial and Single-Cell Analysis Copilot for Core Facilities
Single-cell and spatial transcriptomics are generating data faster than the analysis capacity to make sense of it.
Large-scale cell atlas programs — including initiatives from the Chan Zuckerberg Initiative's CELLxGENE consortium and the Human Cell Atlas — are building reference datasets designed to accelerate drug discovery across the pharmaceutical ecosystem. Meanwhile, spatial transcriptomics platforms from vendors including 10x Genomics (Xenium) and Vizgen (MERSCOPE) are enabling researchers to access broad transcriptomic profiles alongside localized gene expression patterns at increasingly fine resolution.
The downstream problem is that academic core facilities, which run the sequencers for dozens of research groups, don't have the bioinformatics staff to analyse this data at the pace it arrives. QC, cell-type annotation, batch correction, and publication-ready figures are expert-gated tasks. The pharma-focused software vendors ignore this buyer entirely because the deal sizes are smaller.
Foundation models for single-cell biology — including published tools such as scGPT, Geneformer, and scFoundation — support flexible applications ranging from cell typing to analysis of spatial contexts, independent of complex dataset-specific analysis workflows. An agentic tool built on top of these models, designed specifically for core facility workflows, targets a buyer who is chronically underserved and has real willingness to pay. Workflow lock-in and proprietary annotation references compound the moat over time.
5. Multi-Omics Integration and Interpretation for Translational Teams
Translational researchers want to know what their data means for patients. They have genomics data, transcriptomics data, proteomics data, and clinical outcomes data. Integrating those into a coherent picture currently requires a data scientist who understands both the biology and the ML, a combination that's expensive, rare, and fully occupied at any institution that has one.
Emerging trends ranging from multi-omics fusion to foundation models have the potential to advance variant interpretation along multiple strategic axes spanning molecular, computational, functional, and population-level dimensions of clinical genomics. The agentic version of multi-omics integration doesn't just run a pipeline. It surfaces interpretable, outcome-linked hypotheses: here's the pathway implicated across your three datasets, here's the patient subgroup where the signal is strongest, here's the clinical covariate that explains most of the variance.
The moat is twofold. First, the integration logic itself encodes deep domain knowledge that generic ML tooling doesn't have. Second, proprietary linked datasets, built up over multiple customer engagements, make the interpretive models progressively more accurate for specific disease areas. A startup that focuses on oncology translational teams, or rare disease, accumulates a data and model advantage that a general-purpose platform can't replicate from the outside.
6. Pharmacogenomics Clinical Decision Support at the Point of Care
Genotype-guided prescribing has been clinically validated for years. The gap is last-mile deployment: getting the right recommendation in front of the right clinician at the moment of prescribing.
One of the biggest developments in 2026 is the integration of pharmacogenomic data into EHRs. Genetic results are becoming part of active prescribing systems rather than isolated lab reports. When a clinician selects a medication, automated clinical decision support tools can now flag potential gene-drug interactions in real time.
The problem is that most existing implementations are brittle, institution-specific builds requiring large integration projects. Pharmacogenomic implementation barriers exist in the integration of results into EHRs, development and deployment of decision support tools, and building feasible models for ambulatory pharmacogenomic clinics.
The startup opportunity is a copilot that sits at the EHR/pharmacy interface, pulls a patient's genomic profile, and returns guideline-concordant dosing guidance in a format clinicians can act on without leaving their workflow. The moat here is trust and integration depth. A better algorithm alone won't win this. What wins is having your product certified, integrated into the major EHR platforms, and trusted by pharmacy committees, all of which take years to accumulate and can't be replicated by a better model arriving later.
7. Regulatory Submission Copilot for Genomic and AI Diagnostics
Taking a laboratory-developed test or an AI-based diagnostic through FDA 510(k)/De Novo or EU-IVDR approval means assembling analytical validation studies, clinical validation packages, software documentation, and post-market surveillance plans. It's a documentation problem as much as a science problem, and it's one that gets harder as the underlying test or model evolves.
AI has captured a growing share of venture capital investment in recent years, with a significant proportion of those applications in diagnostics. Every one of them will eventually need regulatory approval. The volume of genomic and AI diagnostics seeking clearance is growing faster than the regulatory consulting capacity to support it.
An AI copilot that generates the submission package, tracks it against current FDA/EU-IVDR guidance, and maintains it as the test or model changes addresses a real and growing bottleneck. This is the biotech equivalent of regulated-hardware compliance tooling: it becomes more valuable, not less, as the number of submissions grows. The moat is regulatory trust plus proprietary submission templates and track records built across prior approvals.
8. Applied Metagenomics for Clinical Micro, AMR, and Surveillance
Most metagenomics tooling is built for academic researchers asking curiosity-driven questions. The applied markets are different in character and often more urgent.
Pathogen identification from clinical sequencing, antimicrobial resistance prediction, food safety screening, and wastewater epidemiology surveillance are all markets where the buyer isn't a research group submitting a grant. They're a hospital microbiology lab trying to make a treatment decision, a public health agency monitoring an outbreak, or a food manufacturer managing a recall risk.
Bioinformatics and generative AI are accelerating genetic research, but the tooling built for academic discovery workflows doesn't translate cleanly to these applied contexts. Reference databases calibrated for academic sensitivity miss the clinically important organisms. Reporting formats don't match clinical laboratory requirements. AMR prediction models trained on research isolates perform unpredictably on clinical samples.
The startup opportunity is purpose-built applied metagenomics tooling with reference databases curated for clinical and food safety contexts, reporting designed for regulated environments, and a regulatory positioning strategy from day one. The moat is those applied-domain reference databases and the fragmented buyer base — hospital micro labs, public health agencies, food manufacturers — that the techbio-focused crowd consistently overlooks.
9. Immunoinformatics Tooling for the Long Tail
The immunoinformatics space has a specific structural problem: the well-funded players are building therapeutics, not tools. They're using their neoantigen prediction models, TCR/BCR repertoire analysis pipelines, and vaccine design platforms internally, on their own pipeline, and they have no commercial incentive to productise them for external users.
That leaves academic immunology labs, small biotechs, and contract research organisations using a patchwork of open-source tools, custom scripts, and occasional consulting engagements. None of these buyers are poorly motivated. They're just poorly served.
Investments support the development of advanced bioinformatics tools for drug discovery, personalized medicine, and disease modeling, and immunotherapy is one of the faster-growing areas within that. A focused tooling platform for neoantigen prediction, repertoire analysis, and vaccine design, targeted at academic and small-biotech teams, doesn't need to compete with Genentech's internal tools. It needs to be substantially better than what this buyer currently uses.
The moat is proprietary immune datasets accumulated through customer engagements and the depth of the domain knowledge encoded in the workflows. These are not general ML problems. They require a team that understands HLA binding, clonotype analysis, and immunodominance, and that domain depth is genuinely hard to replicate.
10. Bioprocess Optimization for CDMOs and Biologics Manufacturing
Biologics manufacturing is still largely empirical. Strain selection, cell-line development, fed-batch fermentation optimization, and process QC involve enormous amounts of run data that most facilities have accumulated over years and analyzed poorly.
Biomanufacturing is changing how pharmaceuticals and bio-based materials are produced to increase efficiency and scalability. The AI opportunity in bioprocess isn't drug discovery, which already has well-funded attention. It's the manufacturing layer: using each facility's own historical run data to build predictive models that cut development timelines, reduce batch failures, and flag process drift before it causes a deviation.
The CDMO and biologics manufacturing market is fragmented. Large CDMOs have internal data science teams; the mid-tier and smaller facilities don't, and they're running the same process development challenges at lower margin. An AI layer that integrates with existing LIMS and historian systems, builds predictive models on a facility's own data, and provides actionable process guidance addresses a real operational problem with clear ROI.
The moat is the proprietary process data built up through each customer engagement. A model trained on ten years of a facility's fermentation runs is not something a competitor can replicate by building a better algorithm. The industrial buyer fragmentation is a feature, not a bug: it means no single buyer can build this themselves, and the first platform to achieve critical mass in a specific modality — mammalian cell culture, microbial fermentation, viral vector production — builds an advantage that is difficult to displace.
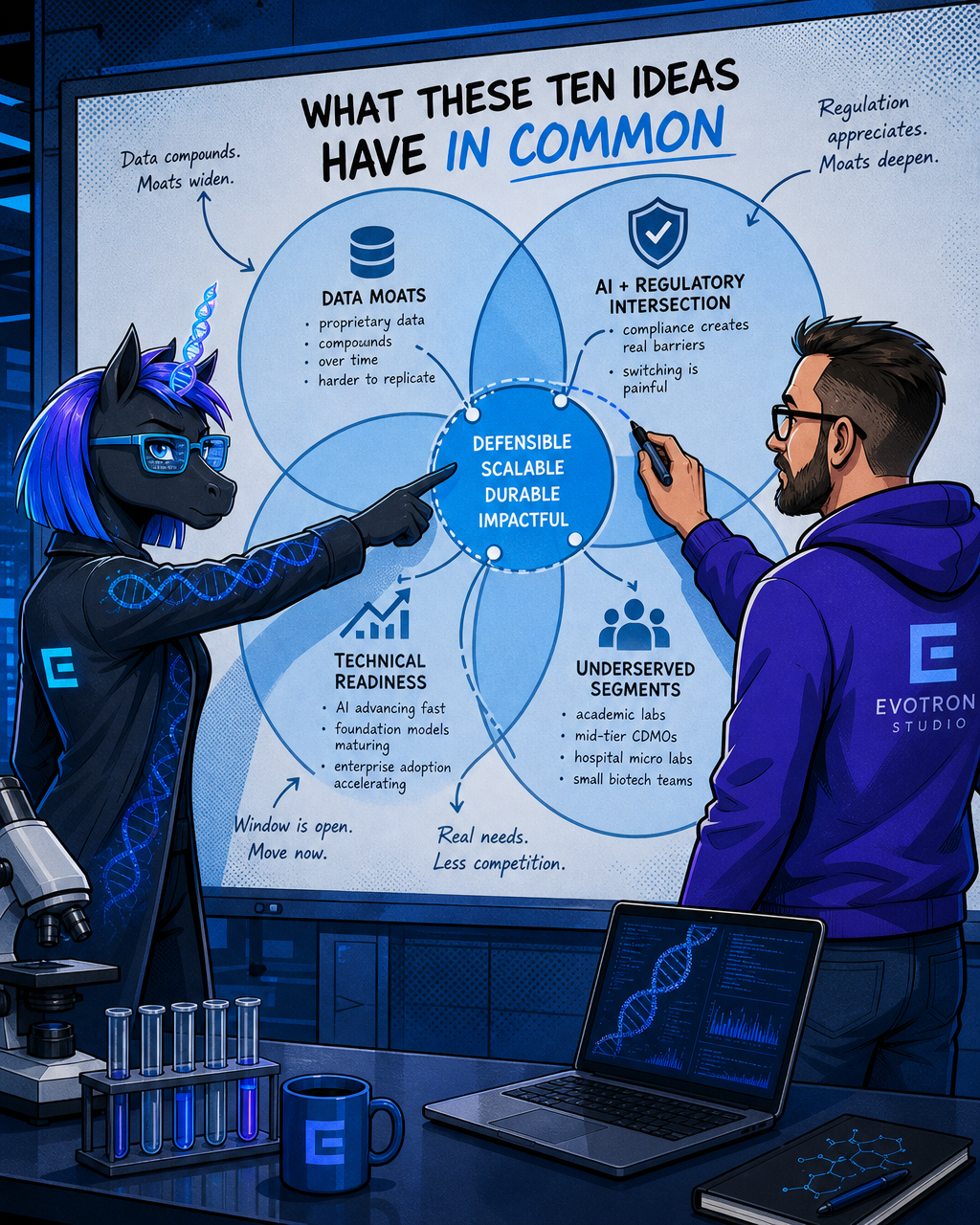
What These Ten Ideas Have in Common
Look across these ideas and a few patterns emerge.
First, the strongest moats are data moats, not model moats. A better algorithm is a six-month advantage. A proprietary database of curated variant annotations, process run data, or immune repertoire profiles is a multi-year structural advantage that compounds with every new customer engagement.
Second, the most defensible ideas sit at the intersection of AI capability and regulatory obligation. Compliance isn't just a cost of doing business in these markets. It's a genuine barrier that makes switching painful once a product is embedded, and it appreciates in value as regulatory requirements grow more stringent.
Third, several of the most compelling opportunities sit in underserved market segments: academic core facilities, mid-tier CDMOs, hospital micro labs, small biotech immunology teams. The large platforms are chasing pharma and large health systems. The long tail has real needs, real budgets, and far less competition.
Finally, the technical readiness window is genuinely open right now. The pace of AI advancement in both academia and industry has far outstripped that of many other disciplines, generating diverse model architectures for single-cell and spatial transcriptomics. Foundation models for biology are crossing from academic novelty into practical tools. Enterprise adoption of AI-driven precision medicine platforms is accelerating, with health systems increasingly signing on to AI-based genomics platforms — a trend reflected in announcements from multiple vendors in the precision medicine space through early 2026.
The founders best positioned to build in these spaces are the ones who already know where the bodies are buried: the bioinformatician who has watched variant curation bottlenecks cause clinical delays, the manufacturing scientist who knows exactly which process parameters matter and why nobody has modelled them properly, the immunologist who has hacked together the same neoantigen pipeline three times across three labs.
The data's validated. The market timing looks right. The remaining question is whether you build it.
If you're a domain-expert founder with a validated bioinformatics problem and want to move from concept to a demo-ready product without assembling a team, Evotron Studio pairs senior operators with an agentic platform to stand up your venture in weeks. Start with a diagnostic engagement to find out if your concept is ready to build.
Evotron Studio
We build and run our own AI-amplified ventures — and bring the same capability into yours.
We build and run our own AI-amplified ventures — and bring the same capability into yours.
Learn more about Evotron Studio and get started today.
Visit Evotron Studio




